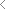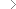„Trust in those who supposedly know – MURRAY, DONDIE, REBECCA“, Solo-Exhibition Falko Alexander Galerie, Ausstellungstext von Julia Stellmann
Unmöglich erscheinende Architekturen legen sich in scharfkantige Falten, fluchten in geometrisch anmutenden Verstrebungen gen dramatischen Wolkenhimmel. Ein muskulöser Arm blitzt hervor, schlanke Säulen flankieren einen Portikus, Lorbeerkranz und Kreuz lösen sich herrschaftlich aus dunkelkaltem Untergrund. Der betrachtende Blick fährt durch alternierendes Spiel der Schatten, streicht über die pupillenlosen Augen eines namenlos Porträtierten. Mit undefinierbarem Pathos aufgeladen erinnern die Architekturen an die Bildsprache vergangener Imperien, könnten gleichsam zukünftige Utopien bezeugen. Sie muten wie konkrete Bildnisse von Herrschern, Heroen an, scheinen politische oder religiöse Aussagekraft zu besitzen, verwehren sich zugleich eindeutiger Zuschreibung. Als in Graustufen gefärbte Bilder erhalten die retro-futuristischen Denkmäler beinah dokumentarischen Charakter, bleiben trotzdem zeitlich unbestimmbar.
Vor dem inneren Auge lösen sich vergleichbar einer Google-Suche im Hirn unzählige Referenzbilder aus dem gedanklichen Undunkel, die gewisse Ähnlichkeiten aufweisen und doch keine eindeutigen Lösungen liefern. Denn die mit den tastenden Augen wie mit den Fingern befühlbaren Texturen, Historie imitierenden Bilder oder in den realen Raum überführten Stickereien vermögen es, das Publikum bewusst zu täuschen – und dringen doch darauf, entlarvt zu werden. Denn im Verwirrspiel mit der Wahrnehmung ist das Erkennen von Irritation elementarer Bestandteil der Arbeiten von Künstler Michael Reisch. Plötzlich stören Bruchstellen, Deformationen, Lücken in der bildnerischen Erzählung den unbedarften Blick auf. Fehlerhafte Muster, non-existente Denkmäler, computergesteuert gefertigte Stickereien gestehen ihre digitale Natur ein.
In Reaktion auf digitale Bilderflut und neue bildgebende Verfahren rief Reisch 2010 seinen persönlichen Nullpunkt der Fotografie aus, fand einen referenzlosen Neuanfang innerhalb des Bildbearbeitungsprogramms Photoshop. Mit letzterem kreierte er optische Interferenzen, die er mittels 3D-Druck als materielle Objekte in die fassbare Realität übertrug. Unsichtbare Daten und Algorithmen wandelten sich somit zu dreidimensionalen Skulpturen, welche sich nun von Reisch „traditionell“ fotografieren ließen. Zwei dieser aus sich selbst heraus generierten Fotografien dienten als Grundlage der in der Galerie Falko Alexander präsentierten Arbeiten. Denn die ausgestellten Bilder, welche auf den ersten Blick wie Fotografien von außerbildlichen Objekten anmuten, stellen sich als KI-generiert heraus. In teils mehrstufigem Prozess verwandeln KI-Diffusionsmodelle die eingespeisten Ausgangsbilder mithilfe von ideologisch aufgeladenen Prompts in neues Bildmaterial. Dabei greift die KI auf eine Black Box aus Informationen zurück, in welcher sich wiederum eigene, schwerlich durchschaubare Ideologien verbergen können. KI führt allerdings auf einem neuen Level fort, was bereits durch Bildbearbeitungsprogramme vorgezeichnet war. Reisch interessierte Fotografie immer schon mehr als Medium der Illusion als der Wahrheit.
Was ist wahr und was fake? Was ist Realität und was Illusion? Fragen, die sich angesichts von Falschinformationen, digital manipulierten Inhalten auch im Alltag immer dringlicher stellen. Politisches Denken und Handeln beruft sich ebenso nicht mehr nur auf reine Fakten. Beim Brexit-Referendum 2016 oder US-Präsidentschafts-Wahlkämpfen spielten stattdessen Emotionen eine bedeutendere Rolle als der Anspruch auf Wahrheit. Dazu kommt ein gefühlter Verlust der Glaubwürdigkeit traditioneller Medienberichterstattung. Entsprechend beziehen immer mehr Menschen dank Filterblasen und Echokammer-Effekt einseitige, teils falsche Informationen aus den sozialen Medien. Sollten wir den vermeintlich Wissenden wirklich vertrauen? Und wer sind die vermeintlich Wissenden? Sind es MURRAY, DONDIE und REBECCA? Ihre Namen können eingebettet in den Titel der Ausstellung samt Anführungszeichen innerhalb der Schau entziffert werden. Dabei handelt es sich um drei von der KI ersonnene Figuren, welche ein Gemisch aus Wissen und Fiktion in einer zugehörigen Soundarbeit verlauten lassen. Dafür speiste Reisch die KI mit wissenschaftlich fundierten Texten bzw. Kritik zur Post-Truth-Bewegung aus dem Bereich der Politik- und Kulturwissenschaften, doch antwortete diese – trainiert auf Hollywood-Drehbücher – mit fiktiven Charakteren und Statements, die Reisch zu oft pathetischen sinnentleerten Dialogen und Bedeutungsblasen weiterverarbeitet hat. Anders als zum Beispiel Fotografie agiert die KI zwar auf der Basis von Fakten, produziert aber letztlich fiktionale Erzeugnisse. Eine ganz eigene Art von Logik wohnt diesem Output inne, der wiederum als Fakten wahrgenommen wird.
In der Ausstellung „Trust in those who supposedly know – MURRAY, DONDIE, REBECCA“ bilden zuletzt zahlreiche iPads eine Front aus flimmernden Bildschirmen, auf denen sich generative Videosequenzen im Loop abspielen. Faltenwürfe, Pferde, Skulpturen, Gesichter, Bilder, Symbole, Strukturen sind in gestaltwandlerischem, fluidem Prozess begriffen. Objekte kollabieren, expandieren oder morphen, fügen sich zu unmöglichen Narrativen. In Sekundenbruchteilen wandeln sie sich von Text zu Bild zu Bewegtbild zu Audio, berauben einander ihrer Bedeutung. Gleichzeitig mutieren Fakten zu Fiktion und diese wiederum zu Fakten. Alles ist möglich, sodass Reischs Evolution der Bilder sich eher rhizomatisch als linear beschreiben lässt. Sollten wir wirklich den vermeintlich Wissenden vertrauen?
Julia Stellmann, 11-2024